CloudDrift, a platform for accelerating research with Lagrangian climate data#
Version: 0.34.0#
Lagrangian data typically refers to oceanic and atmosphere information acquired by observing platforms drifting with the flow they are embedded within, but also refers more broadly to the data originating from uncrewed platforms, vehicles, and animals that gather data along their unrestricted and often complex paths. Because such paths traverse both spatial and temporal dimensions, Lagrangian data can convolve spatial and temporal information that cannot always readily be organized in common data structures and stored in standard file formats with the help of common libraries and standards.
As such, for both originators and users, Lagrangian data present challenges that the CloudDrift project aims to overcome. This project is funded by the NSF EarthCube program through EarthCube Capabilities Grant No. 2126413.
Scope and Key Features#
The scope of the Clouddrift library includes:
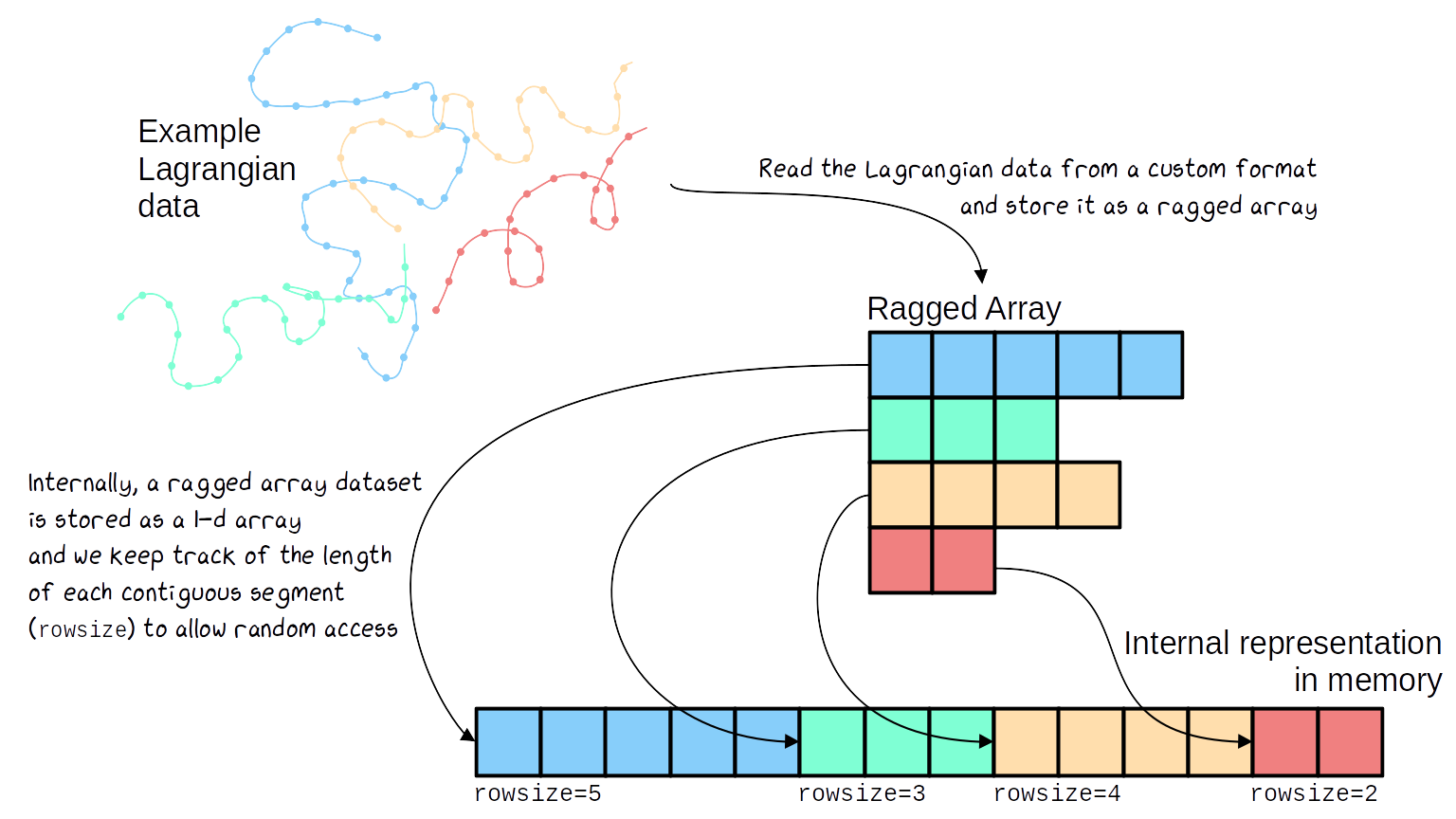
Working with contiguous ragged array representations of data, wether they originate from geosciences or any other field. Ragged array representations are typically useful when the data lengths of the instances of a feature (variable) are not all equal. With such representations the data for each features are stored contiguously in memory, and the number of elements that each feature has is contained in a count variable which Clouddrift calls rowsize.
Delivering functions and methods to perform scientific analysis of Lagrangian data, oceanographic or otherwise, structured as ragged arrays or otherwise. A straightforward example of Lagrangian analysis provided by Clouddrift is the derivation of Lagrangian velocities from a sequence of Lagrangian positions, and vice versa. Another more involved example is the discovery of pairs of Lagrangian data prescribed by distances in space and time. Both of these methods are currently available with Clouddrift.
Processing publicly available Lagrangian datasets into the common ragged array data structure and format. Through data adapters, this type of processing includes not only converting Lagrangian data from typically regular arrays to ragged arrays but also aggregating data and metadata from multiple data files into a single data file. The canonical example of the Clouddrift library is constituted of the data from the NOAA Global Drifter Program (see Motivations below).
Making cloud-optimized ragged array datasets easily accessible. This involves opening in a local computing environment, without unnecessary download, Lagrangian datasets available from cloud servers, as well as opening Lagrangian dataset which have been seamlessly processed by the Clouddrift data adapters.
CloudDrift’s analysis functions are principally centered around the ragged-array data structure:
Motivations#
The Global Drifter Program (GDP) of the US National Oceanic and Atmospheric Administration has released to date nearly 25,000 drifting buoys, or drifters, with the goal of obtaining observations of oceanic velocity, sea surface temperature, and sea level pressure. From these drifter observations, the GDP generates two data products: one of oceanic variables estimated along drifter trajectories at hourly time steps, and one at six-hourly steps.
There are a few ways to retrieve the data, but all typically require time-consuming preprocessing steps in order to prepare the data for analysis. As an example, the datasets can be retrieved through an ERDDAP server, but requests are limited in size. The latest 6-hourly dataset is distributed as a collection of thousands of individual NetCDF files or as a series of ASCII files. Until recently, the hourly dataset was distributed as a collection of individual NetCDF files (17,324 for version 1.04c) but is now distributed by NOAA NCEI as a single NetCDF file containing a series of ragged arrays, thanks to the work of CloudDrift. A single file simplifies data distribution, decreases metadata redundancies, and efficiently stores a Lagrangian data collection of uneven lengths.